Recursive URL Memory
Overview
Recursive URL memories let Hana ingest whole sections of a public website from a single starting link, so she can answer follow-up questions with fresh, source-backed context.
-
Ingest public URL: Hana begins with the page you supply and follows allowed links within the same domain when permitted. Check how you can ingest url
-
Capture an entire section: Every qualifying page becomes a searchable memory so Hana can recall the right snippets when teammates ask for help in chat or reports. Check how you can ask help after ingesting the memory
-
Respect customer boundaries: The crawl never follows links to outside domains and honours any folders you explicitly exclude. Check how you can setup to include or exclude urls
Plan-based behaviour
| Plan tier | Available options | Crawl experience |
|---|---|---|
| Free | Primary URL. The depth profile is fixed to Basic. | Hana reads the primary page with the fast speed-first reader |
| Basic | Primary URL. The depth profile is fixed to Basic. | Hana reads the primary page with the fast speed-first reader |
| Pro | Primary URL, include/exclude paths, crawl guidance, category tag, extra depth and use-case instruction. Crawl sub-pages and the Advanced depth profile are unlocked. | Hana uses the richer best-quality reader by default, explores up to three in-domain levels (max 200 pages), and honours every filter the customer sets. |
Access and permissions
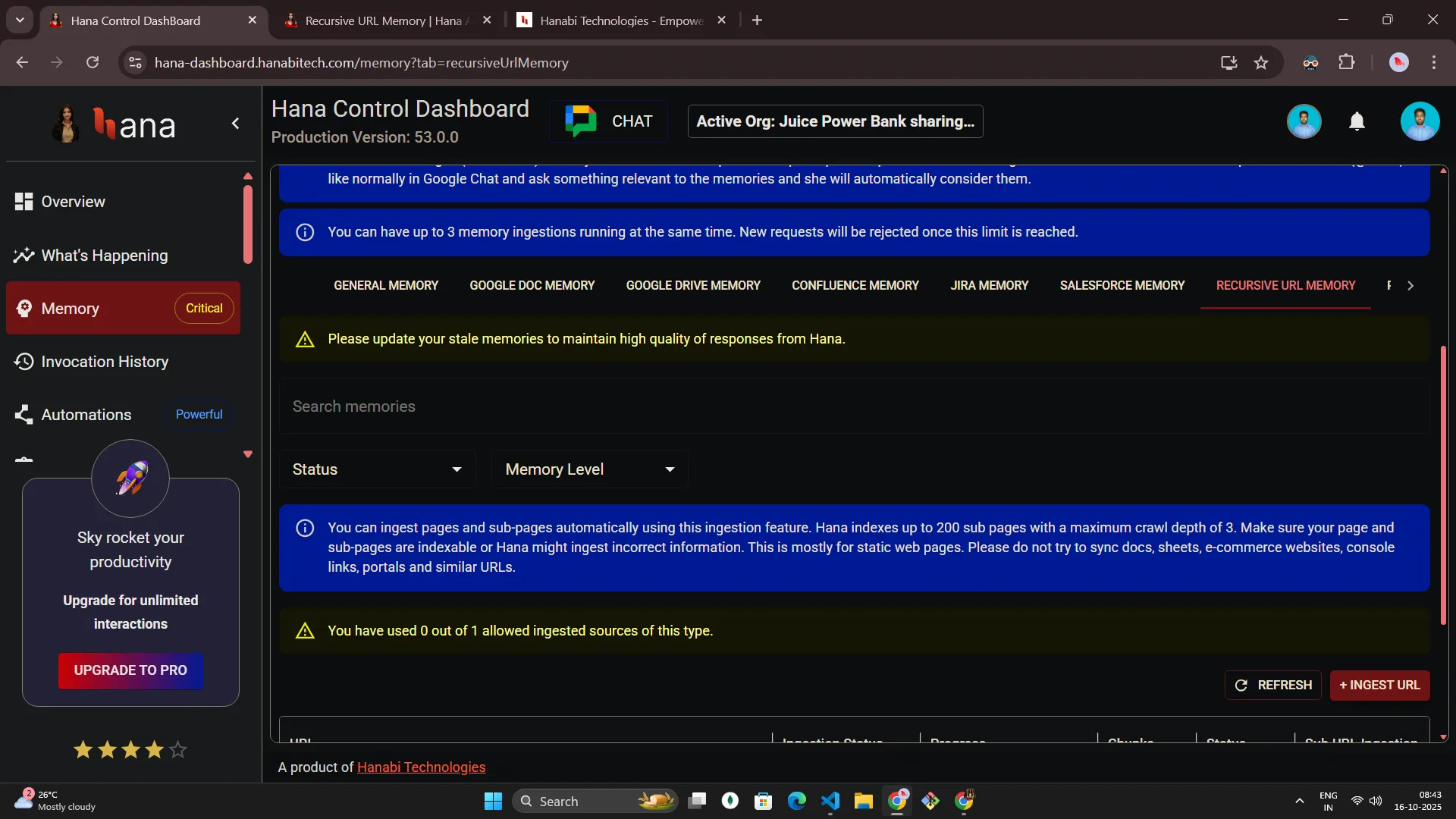
- Only Admins can view or manage the Recursive URL tab. Page will look like below for "ADMIN" role.
-563fde8504f1ab7d989ddf8d3d67aeb1.webp)
- Other roles see a not-authorized message and all primary actions stay disabled until someone with the required access signs in. Page will look like below for "USER" role.
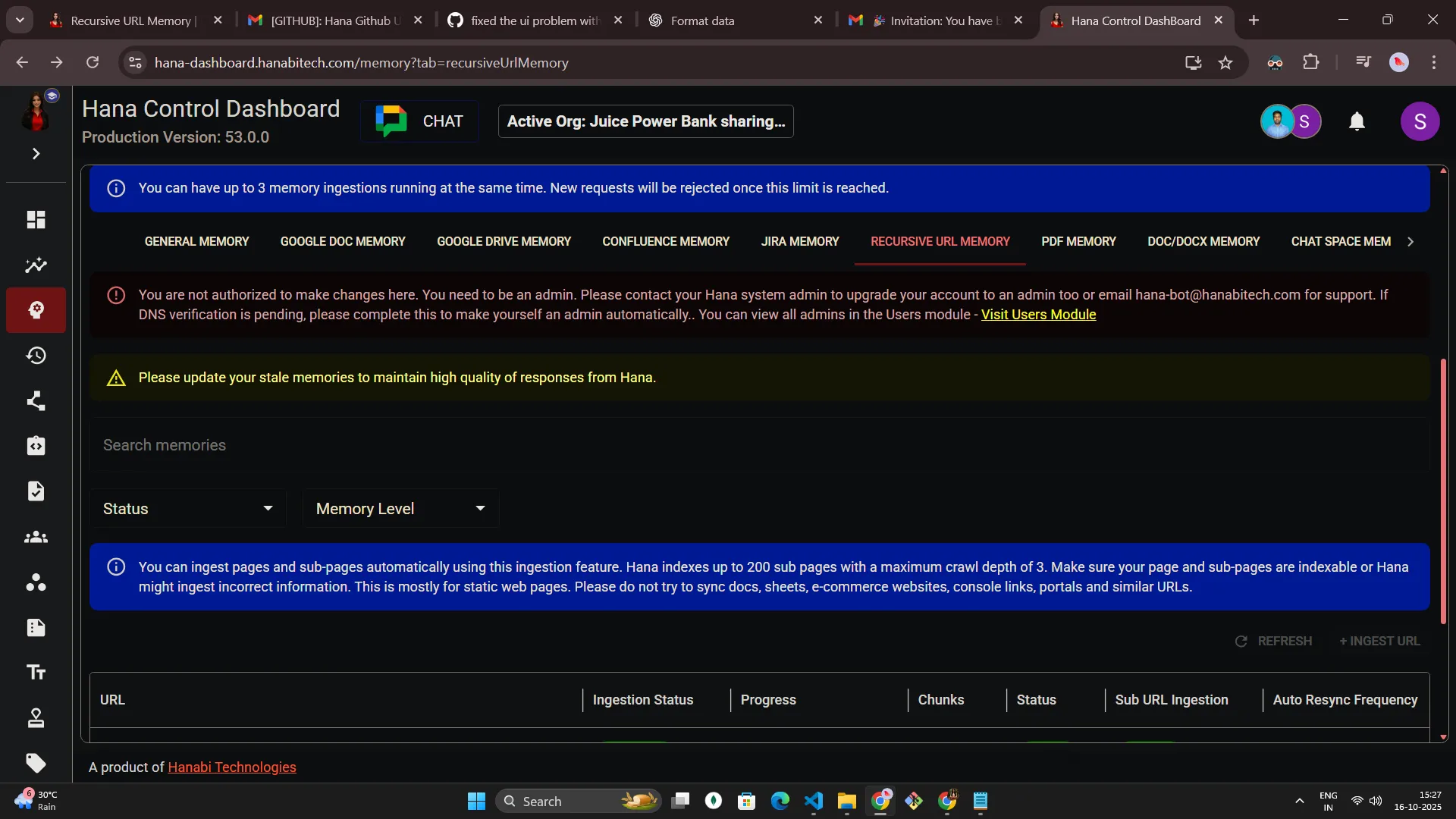
Adding a recursive URL memory
- From the Memory section, open the Recursive URL Memory tab.
- Select + Ingest URL and review the safety notice.
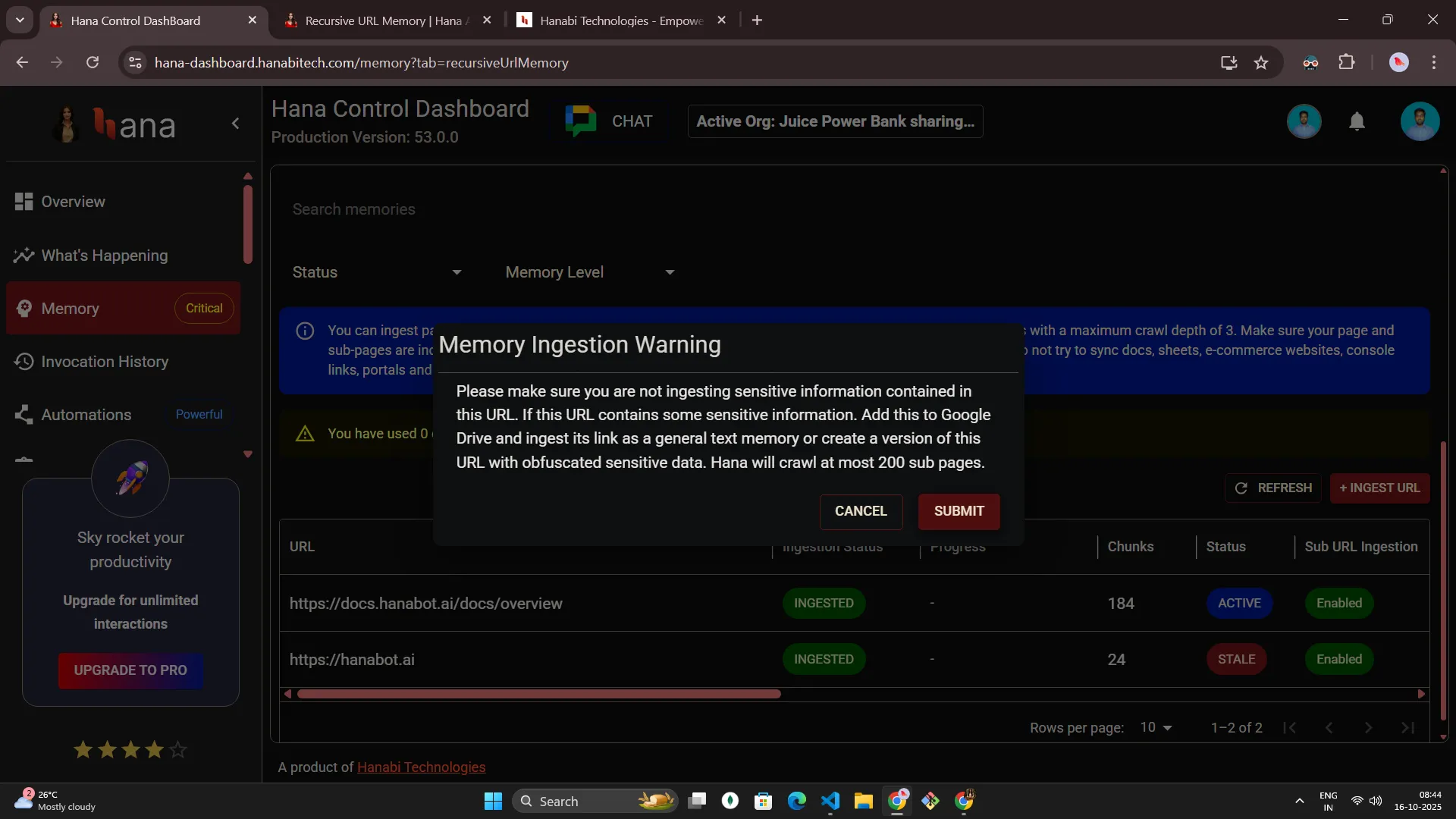
- Complete the form and submit.
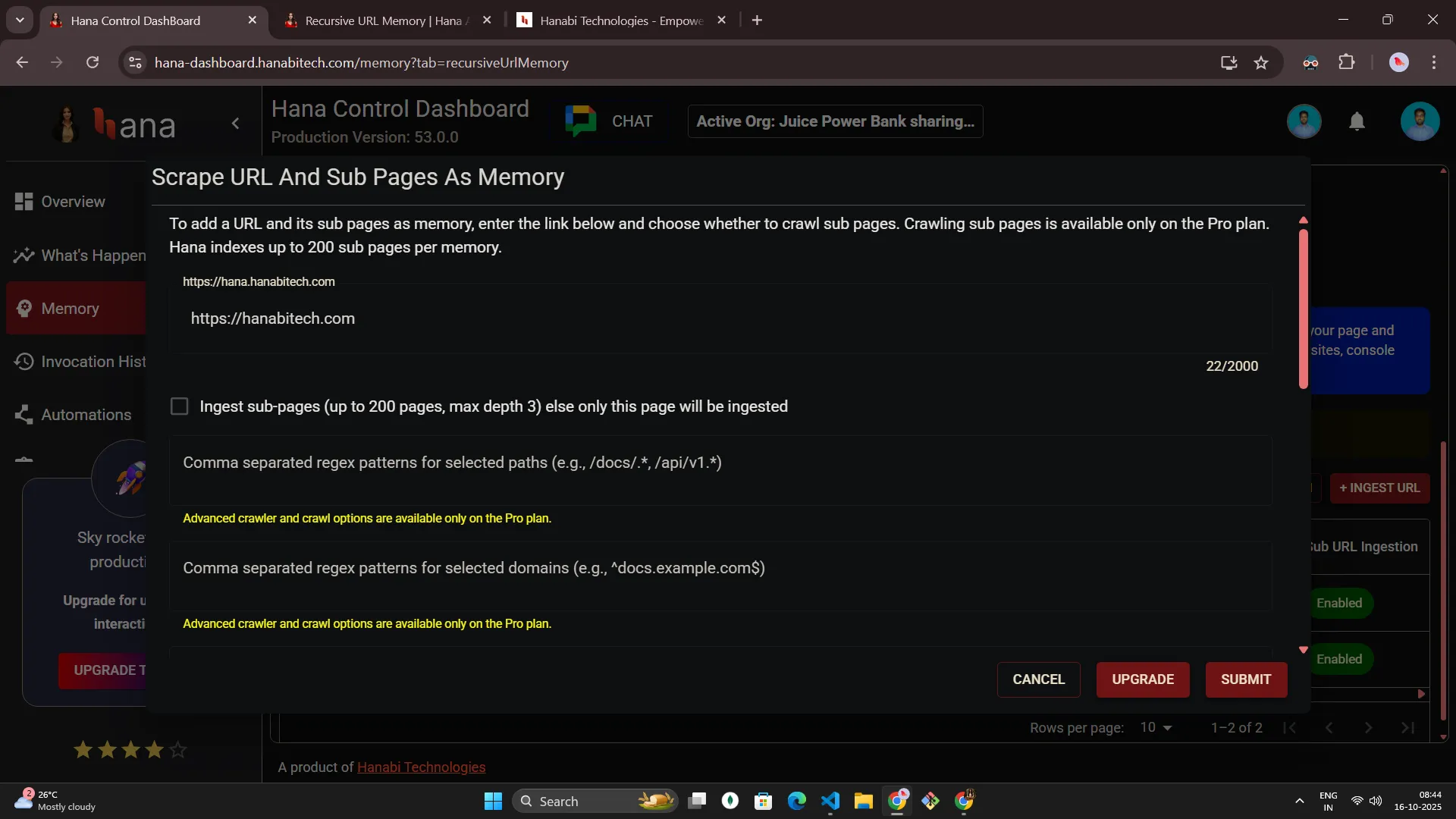
- After you submit, Hana confirms that ingestion has started and returns you to the list view. The new batch appears immediately with an In Progress status and a progress indicator that updates as pages are captured.
-cc0ab45c2e55a0a40188ef248c5d6c36.webp)
-26d1bc8531d6424fa90e7e57d8bbc2d0.webp)
- Once the memory ingestion is complete, it will be moved to the Ingested state.
-0eeae06fe9b8d592cf276c99191d31e4.png)
Recursive urls memory ingestion controls at a glance
| Form control | What it unlocks for users | Default & limits | Plan availability |
|---|---|---|---|
| Primary URL (required) | Starts the crawl on the page that matters most so Hana ingest the right content first. | Must be a public, reachable URL. Hana always checks reachability and safety. | All plans |
| Crawl sub-pages | Expands coverage to supporting pages under the same domain for broader knowledge. | Follows in-domain links up to 3 levels deep and stops at 200 pages per batch. Off for Free/Basic. | Pro |
| Include / exclude paths or domains | Highlights valuable sections and leaves out noisy or sensitive areas. | Allow-list entries are prioritised; deny-list entries are skipped entirely. | Pro |
| Crawl guidance | Allows you to instruct the crawler where to focus (e.g. “crawl pricing pages”) so that extracted content aligns with those priorities. | Up to 1,000 characters. | Pro |
| Category tag | Guides the crawl toward pages belonging to a certain content category (e.g. “Documentation”, “Blog”, “Pricing”) for more focused results. | Stored in the batch metadata. | Pro |
| Crawl depth profile | Chooses between a quick skim and a richer read when the plan supports it. | Basic = fast speed-first reader. Advanced = best-quality reader with deeper context. | Pro (Free/Basic locked to Basic reader) |
| Use-case instruction | Write the instruction when to recall ingested memory. | Up to 2,000 characters. Displayed in batch and memory views. | Pro |
Primary URL (required)
- Why it matters: Point Hana at the exact page that matters most; she begins there before exploring anything else.
-0bca887644cc6af21ac5e21271acf022.png)
-
Plan availability: No restrictions—every team must supply it, and the same validation applies across plans but there is a usage limitations for Free/Basic plans. Upgrade to Pro plan for for a seamless experience — no limits, more control, deeper crawling.
-
Behind the scenes: Once Hana verifies the URL is reachable, safe, and free of login walls, Hana ingest the confirmed address to the batch.
Crawl sub-pages (optional)
- Why it matters: “Turn this on when you want Hana to cover the rest of the site under that same domain.”
-e84f7822da1bbcab9276b5fed4dbe5e6.webp)
-
Plan availability: Enabled for Pro users. No available for Free and Basic plans.
-
Behind the scenes: Hana stays inside the submitted domain, honours any path filters, and queues pages up to three levels deep with a 200-page ceiling so results stay focused.
Include or exclude paths and domains
- Why it matters: “List paths or subdomains you do—or don’t—want so Hana focuses on what matters.”
-c322bdf4ff759cfafc026da78d75b9d2.webp)
-ffc8ffaba7ffc1701c0f32e77495d92c.webp)
-f1b963f1c58f7dbd21d1c61a14975227.webp)
-072638f59d1764659a77f659ad68099f.webp)
-34d4d3ee617b109bf502719eadf08dc3.webp)
-5ebf2e87c3d03405f0dfb079b24fbaab.webp)
- Plan availability: Enabled for Pro users. No available for Free and Basic plans.
- Behind the scenes: Hana stores both lists with the batch, prioritises allow-listed links before each fetch, and skips anything that matches the exclusion list so unwanted pages never become memories.
Crawl guidance
- Why it matters: “Provide a short instruction like “prioritize pricing pages” to guide crawlers toward the sections you care about.”
-6129c97b822e618ab1614c1b8ceda3de.webp)
- Plan availability: Enabled for Pro users. No available for Free and Basic plans.
- Behind the scenes: The guidance text influences which pages crawlers visit first and how content is summarized, so the memories produced stay aligned with your goals.
Category tag
- Why it matters: You choose a category (like “Documentation”, “Blog”, “Pricing”) to guide which kinds of pages the crawler should focus on.
-a262bb20af0fc4316d6da9509b102187.png)
-4721c729d1186e919ed2570316e700b7.png)
- Plan availability: Enabled for Pro users. No available for Free and Basic plans.
- Behind the scenes: The category is passed into the crawl input schema as a “categories” parameter, and the crawling engine uses it in its heuristics for filtering and prioritizing URLs
Crawl depth profile
- Why it matters: “Choose Basic for a quick skim or Advanced for richer notes if your plan allows.”
-72523115529f66db54369cb0b82e5bdf.webp)
- Plan availability: Free and Basic remain on Basic. Pro can switch between Basic and Advanced.
- Behind the scenes: Hana maps the selection to the reader service: Basic invokes the fast
speed-firstreader, while Advanced triggers thebest-qualityreader that waits for slower-loading pages and records extra context before summarising.
Use-case instruction
- Why it matters: “Share when Hana should recall these memories—think ‘Use for security questionnaires.’”
-7f9a69c0de10e36cbf3c805c26306979.webp)
-605c76f710f1a11b6273d7af66717842.webp)
- Plan availability: Optional for all plans (up to 2,000 characters).
- Behind the scenes: Hana saves the note with the batch details and displays it alongside each memory so collaborators understand the intended use immediately.
- Encourage teams to double-check their include and exclude lists before submitting to keep the crawl focused on the right pages.
- Longer crawls may continue in the background. Users can navigate away and return later—the batch keeps processing.
Monitoring ingestion batches
- The list loads automatically when the page mounts and re-fetches whenever any batch is processing so progress bars remain accurate.
- Keyword search remembers the most recent query per user. Adjusting status or memory-level filters resets pagination so you see fresh results from page one.
-f2ff1c326f57ded91cf9dfa14ae6f11e.png)
- Server-side pagination keeps the table responsive on large organisations. Use Refresh to fetch the latest data or Reset in the search bar to clear active filters while preserving your saved query for later.
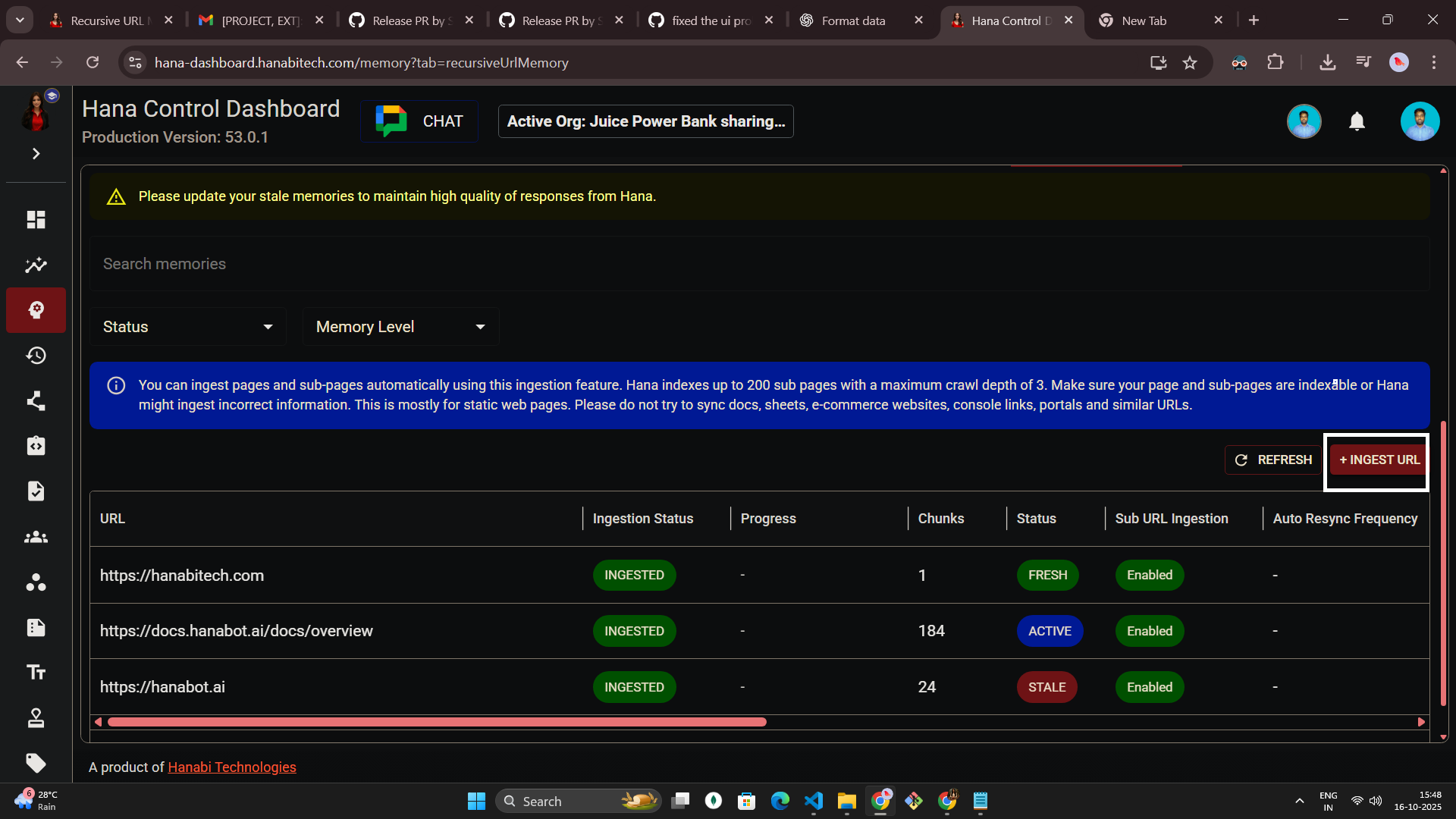
- Columns display rich context, display title, ingestion status and progress, chunk count, freshness, whether sub-pages were crawled, auto-resync cadence, creator and last editor, last sync time, next scheduled sync, share scope (“Just myself” or “Org”), and a global toggle.
Managing a batch
Each row’s action menu adapts to the user’s role, the memory’s share scope, and the ingestion state. Available actions include:
- View Chunks: Inspect the individual knowledge chunks created from the crawl.
-276e9da36e532b5f2895718605d26016.webp)
-d78cb930fbfd7baa5f695a6cba5dec60.webp)
-69110558da89a6fce745f56429887356.webp)
- Sync: Re-run ingestion on a completed batch to refresh content. Users on any plan can sync at any time to refresh memories after a website update or enable auto resync.
-73dfe2557349e7d76aa5d41eb6de3d2d.webp)
-8d57c7e3b171b4decebab69750700481.webp)
- Edit Title: Update the display name that appears in the list.
-4e4550bdbd807925dcfdb5ba1af9fa8e.webp)
-156f241ada6eadfa2e5683c2b9c5759e.webp)
- Auto Resync: Configure an automatic refresh cadence (details below).
-6db3e5b4e317f75d8dc0934c4c1e7dc7.webp)
-cc46b625c4b94ed6a846c2c5480526e5.webp)
-9b00910f57df125caea57ce0f7818431.webp)
-932348fa96f870ad82c8e34933dde87a.webp)
- Disable Auto Resync: Disable automatic refresh cadence (details below).
-803080bb6310e8955bb88acc906c14e0.webp)
-9a2f6cc100e9d79000dd01be3a4dfc6a.webp)
- Abort: Stop an active crawl.
-3039c23bc203b7fecca34f81c0a32ba2.webp)
- Retry Ingestion: Re-queue failed or aborted batches.
-be303ab33a17de6ea7246838fda44794.png)
- Delete: Remove completed or failed batches and their memories.
-fdd9607519a924839f80471c2d82f609.webp)
-c940b160b1b5becbfeba7a2892299af5.webp)
- Copy Source URL: Quickly copy the original URL to your clipboard.
-0aaf8a02509a9229772be0cf03eb034d.webp)
- View URLs: Review the captured links once ingestion is complete.
Quotas, reminders, and safeguards
- A quota banner tallies how many recursive URL sources have been used versus the organisation’s allowance so admins can plan ahead.
- Stale batches surface a reminder to sync them for fresher answers.
- Erroring batches display a callout that recommends contacting support.
- Hana blocks unsafe or disallowed websites before any content is fetched and restricts crawling to public, login-free pages.
- Duplicate crawls for the same URL cannot run simultaneously, preventing duplicate charges and unnecessary load.
From chat — quick invocations
Examples below show only @Hana … invocations. Outputs are intentionally omitted.
@Hana what does our website say about refunds? Use the website memory
@Hana summarize the features listed on our product pages
@Hana find pricing details from the ingested site and outline tiers
Troubleshooting
- Nothing was captured: Confirm the site is publicly accessible. Password-protected or gated pages cannot be crawled.
- Important pages missing: Add those folders to the include list (or remove them from the exclude list) and run the crawl again.
- Too much noise: Refine the exclude paths to focus on the sections that matter.
- Long-running crawl: Large sites can take time. You can leave the page; progress and results persist automatically.